講演者: 松田孟留氏(東京大学 情報理工学系研究科 助教)
演題: 特異値縮小型事前分布と経験ベイズ行列補完
講演概要: 行列型のデータは低ランク性を有することが多い。本講演では、低ランク性を活かした統計手法について紹介する。前半では、特異値縮小型事前分布の理論について解説する。これは低ランク行列の空間への縮小を達成する優調和事前分布であり、Steinの事前分布の自然な拡張になっている。この事前分布によって、行列変数の正規分布に対するミニマックスなベイズ推定量およびベイズ予測分布が得られる。たとえば多変量線形回帰では回帰係数行列が低ランクとなりやすい(縮小ランク回帰)が、特異値縮小型事前分布はこのような状況で特に有効である。後半では、経験ベイズ法による行列補完について紹介する。行列補完とは行列型データの観測成分をもとに未観測成分を推定する問題であり、商品推薦など多くの応用をもつ。この問題に対して、簡潔な階層モデルに基づいた経験ベイズ法のアルゴリズムを提案し、実際に低ランク性を活かした補完が達成されることを人工データ・実データを用いた実験によって確認する。
13:30-14:30
Presenter: [Prof. Partha Lahiri] (Joint Program in Survey Methodology (JPSM) and Department of Mathematics, University of Maryland, College Park, USA)
Title: Small Area Estimation in Presence of Linkage Errors
Abstract: Small Area Estimation is in high demand due to its usefulness in policy making and regional planning. Availability of good auxiliary data is an important component of Small Area Estimation. In the age of big data, we can get access to unprecedented amount of data. The challenge is how to combine data from multiple sources. One potential solution to this problem is record linkage, which is a statistical methodology to link records from multiple sources representing the same population unit. Huge literature is available for both small area estimation and record linkage. But until my keynote address at the 2017 SAE meeting in Paris, there was no suggestion to combine these two important research areas. In this paper, we suggest a unified way to integrate small area estimation with record linkage. Linkage errors are inevitable in the linked data sets because of the unavailability of error-free unique identifiers and because of possible errors in measuring or recording. In presence of linkage errors, small area estimators are subject to a substantial increase in mean square error. Hence, linkage errors should not be ignored when conducting small area estimation. To correct for linkage errors in small area estimation, we propose a general model that integrates small area estimation model, linkage error model and record linkage latent class model. The proposed model accounts for uncertainty in both record linkage process and small area estimation. We propose an estimating-equation-based approach to parameter estimation and and jackknife method of mean square error calculation. A Monte Carlo simulation study is performed to evaluate our proposed methods. Several methods for computation simplification are also provided. The talk is based on collaborative research with my former PhD student Dr. Ying Han.
14:30-15:30
Presenter: Dr. Masayo Y. Hirose(Kyushu University)
Title: A Parametric Empirical Bayes Confidence Interval in the Presence of High Leverage for Area Level Model
Abstract: Parametric empirical Bayes confidence interval is widely used especially when the sample size within each area is not large enough to make reliable direct estimates. Especially, there are already exist several second-order corrected parametric Bayes confidence intervals which asymptotically achieves a smaller length than that of the confidence interval based on the direct estimates. However, these intervals may have several practical issues with finite number of areas. In this talk, we will introduce a new parametric empirical Bayes confidence interval which achieves several properties even in the presence of high leverage and small number of areas. Moreover, we will also mention our confidence interval being more tractable, compared with some existing intervals. Furthermore, we will also report the results of our simulation study for showing overall superiority of our confidence interval method over the other methods.
15:30-15:45
break
15:45-16:45
Presenter: Dr. Shonosuke Sugasawa (Center for Spatial Information Science, The University of Tokyo)
Title: An Approximate Bayesian Approach to Regression Estimation with Many Auxiliary Variables
Abstract: Model-assisted estimation with complex survey data is challenging because the sampling design can be informative, and ignoring it may produce misleading results. Also, when there are many auxiliary variable, selecting significant variables associated with a response variable would be taken into account to achieve efficient estimation of population parameters of interest. In this paper, we formulate the survey regression estimator in the framework of Bayesian inference and incorporate shrinkage prior for regression coefficients to precisely estimate regression coefficients under many auxiliary variables, which enables us to get not only efficient point estimates but also reasonable credible intervals for population means.
18:00-20:00
welcome dinner
講演者: 野間久史氏(統計数理研究所 准教授)
演題: Precision Medicine, Comparative Effectiveness Researchとデータサイエンス
講演概要: 先端的な科学技術の発展および社会経済情勢の著しい変化によって、医学・医療に求められる課題は高度化・複雑化が進んでおり、その難解な問題の解決のためにデータサイエンスの役割は必須のものとなっています。本講演では、特に、Precision Medicine, Comparative Effectiveness Researchの2つのトピックについて、近年の研究の動向について概説するとともに、演者が行ってきた方法論研究の成果を平易に解説します。
講演者: 片山翔太氏(東京工業大学 工学院 経営工学系 助教)
演題: セルワイズな外れ値に対してロバストなスパースグラフィカルモデリング
講演概要: パラメータを正確に0と推定できるスパースモデリングの発展によって,大規模データに対するグラフィカルモデルの探索が容易となった.一方でデータの大規模化に伴う新たな問題も生じている.そのひとつがデータ行列に対するセルワイズな外れ値の混入である.このような状況では,あるサンプルの変数すべてを除外もしくはその重みを小さくする従来のロバスト推定は,データの情報損失が著しく,適切な方法とは言い難い.本発表ではまず,スパースなグラフィカルモデリングを達成できる主要な方法論について説明し,そのロバスト化についての最近のトピックを概観する.最終的に,既存研究を踏まえながら,セルワイズな外れ値に対してロバストな方法論を新たに構築する.これは,統計数理研究所の藤澤教授およびワシントン大学のDrton教授との共同研究である.
講演者: 清野 健氏(大阪大学 大学院基礎工学研究科 教授)
演題: ウェアラブル生体センサとIoTを活用した実世界データ分析とその応用
講演概要: ウェアラブル生体センサとIoTデバイスを内蔵したスマート衣料が開発・販売されるようになっている.そのようなスマート衣料を活用することで,従来は計測が困難であった日常活動中の生体情報を連続的に計測できるようになるため,遠隔医療診断や日常の健康管理への応用が期待されている.本講演では,医療的視点での応用だけでなく,職場でのミスや事故発生のリスク低減といった労働環境での利用など,スマート衣料の可能性の広がりを紹介する.
Presenter: Dr. Jorge Tendeiro(Faculty of Behavioural and Social Sciences, University of Groningen)
Title: Three-mode Principal Component Analysis (3MPCA) and Item Response Theory
Abstract: My talk is divided in two parts. In the first part I will offer an overview over some of my findings in three-way component analysis, which is the topic that I focused on during my Ph.D. In particular, I will present some results revolving around the issues of simplicity and optimizing the search for global minima. The second part of my talk will focus on research within item response theory (IRT), which is the field where I have being working on in the last years. I will introduce the nuts and bolts of IRT, as well as some results based on person-fit analysis, which provides a means of detecting atypical response patterns of tests or questionnaires.
Presenter: Dr. Rei Monden(Faculty of Medical Sciences, University of Groningen)
Title: 3MPCA applied to clinical longitudinal data and Bayesian estimation for the efficacy of antidepressants
Abstract: I will give a presentation about the studies where I applied Three-mode Principal Component Analysis (3MPCA) to clinical data. More specifically, 3MPCA was applied to various longitudinal datasets collected from Major Depressive Disorder patients. 3MPCA decomposes depression into homogeneous entities, while accounting for the interactions between different sources of heterogeneity. The results indicated the utility of the technique to investigate the underlying structure of complex psychopathology data. As a side, I will also discuss shortly about Bayesian approach to evaluate efficacy of FDA-approved antidepressants.
講演者: 服部 聡氏(大阪大学 大学院医学系研究科 教授)
演題: 診断法研究のメタアナリシスにおける公表バイアスの影響評価
講演概要: メタアナリシスとは、複数の医学研究の統計解析結果を併せて分析することで、より強固な医学的証拠を得るための方法であり、治療効果の評価に対して極めて広範に用いられている。メタアナリシスは医学論文で公表された統計解析結果をもとに実施されるが、科学的にインパクトのある結果が論文として採択されやすいため、偏ったサンプリングに基づく不完全データを対象にすることになる。本研究では、診断法研究のメタアナリシスにおける公表バイアスの問題を取り扱う。診断法研究のメタアナリシスでは、要約ROC曲線の方法が有効な方法を与え、広く用いられている。本研究では要約ROC曲線に対する公表バイアスの影響を評価する感度解析法を提案する。要約ROC曲線に対しては、funnel plotなどの通常のメタアナリシスでの基本的な道具が適用できず、提案法が公表バイアスの影響を評価する最初の方法を与える。実データ解析を通じて提案法の有用性を示し、問題点と今後の課題を議論する。
講演者: 坂本康昭氏(アクサ損害保険(株) データサイエンティスト)
Title: Becoming Star Data Scientist
Abstract: このlectureでは、米国におけるdata scienceの動向とアクサ損害保険のデータサイエンスチームの取り組みを中心に、data scientistの育成プログラムやキャリアについて話します。このlectureのobjectiveはスターdata scientistに必要なスキルやマインドセットの理解を深め、data scienceの未来をリードする人材育成に貢献することです。
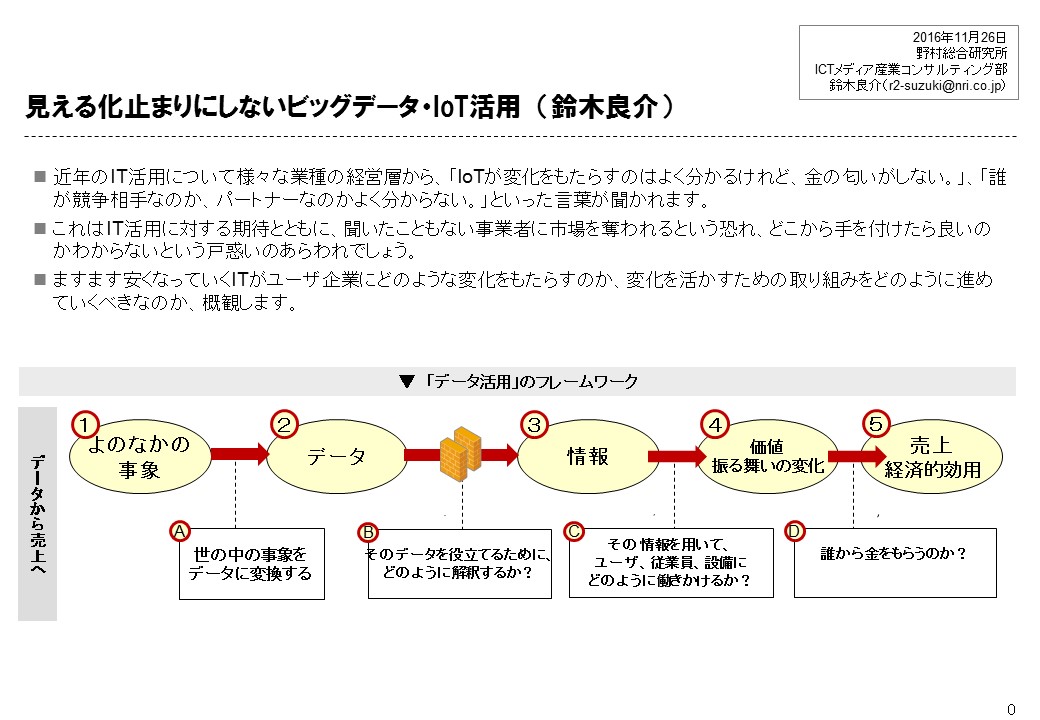
講演者: 鈴木良介氏(野村総合研究所(NRI), 主任コンサルタント)
演題: 見える化止まりにしないビッグデータ・IoT活用
講演概要: 近年のIT活用について様々な業種の経営層から、「IoTが変化をもたらすのはよく分かるけれど、金の匂いがしない。」、「誰が競争相手なのか、パートナーなのかよく分からない。」といった言葉が聞かれます。これはIT活用に対する期待とともに、聞いたこともない事業者に市場を奪われるという恐れ、どこから手を付けたら良いのかわからないという戸惑いのあらわれでしょう。ますます安くなっていくITがユーザ企業にどのような変化をもたらすのか、変化を活かすための取り組みをどのように進めていくべきなのか、概観します。one-page introduction
Presenter: Vladimir Ulyanov(Moscow State University and National Research University Higher School of Economics; Professor)
Title: Bootstrap confidence sets for spectral projectors of sample covariance
Abstract: Let X_1, ... ,X_n be i.i.d. sample in R^p with zero mean and the covariance matrix S. The problem of recovering the projector onto the eigenspace of S from these observations naturally arises in many applications. Recent technique from [Koltchinskii and Lounici, 2015b] helps to study the asymptotic distribution of the distance in the Frobenius norm between the true projector P_r on the subspace of the r th eigenvalue and its empirical counterpart \hat{P}_r in terms of the effective trace of S. This paper offers a bootstrap procedure for building sharp condence sets for the true projector P_r from the given data. This procedure does not rely on the asymptotic distribution of || P_r - \hat{P}_r ||_2 and its moments, it applies for small or moderate sample size n and large dimension p . The main result states the validity of the proposed procedure for nite samples with an explicit error bound on the error of bootstrap approximation. This bound involves some new sharp results on Gaussian comparison and Gaussian anti-concentration in high dimension. Numeric results confirm a nice performance of the method in realistic examples. These are the joint results with Prof.V.Spokoiny (WIAS, Berlin, Germany) and Dr A. Naumov (Skoltech, Moscow, Russia)
講演者: 並木正之氏(Tableau Japan 株式会社)
演題: ビジネスで活用されるデータ分析ツール「Tableau」のご紹介
講演概要: ダイナミックに変化する市場で迅速な意思決定を行うためには、ビジネスの現場の担当者がデータを駆使して業務を遂行することが重要です。 Tableauを使うことで、誰もがデータを早く簡単に可視化し、そこからビジネスを成長させるヒントを得ることができます。世界で50,000社を超えるお客様が導入しているTableauの魅力について、デモを交えながら紹介します。one-page introduction
Presenter: Ke-Hai Yuan(University of Notre Dame, Professor)
Title: Power Analysis for Structural Equation Modeling with Incomplete Data from an Unknown Population Distribution
Abstract: PowerAnalysis1(abstract).pdf
Presenter: Yutaka Kano(Osaka University, Professor)
Title: Effects of inclusion of auxillary variables in the analysis of missing data
Abstract: Part of the talk presented at the IMPS2015 at Beijing, China
講演者: 吉田裕亮氏(お茶の水女子大学 理学部 情報科学科,教授,理学部長)
演題: 成分間に相関のあるランダム行列の時系列モデル解析への応用
講演概要: 成分間に相関のあるランダム行列から Wishart 型ランダム行列を構成する. 本研究では, 特に行方向に MA モデルで与えられる相関から始める. このときその固有値経験分布の極限分布が自由複合 Poisson 分布になることが漸近自由性を用いて比較的簡単に導けることを述べ, その分布の高次モーメントがモデルのパラメータで完全に記述できることみる.
さらに, これらモーメントのゆらぎ (fluctuation) に関する組み合わせ論的公式を紹介し、fluctuation と与えられた時系列モデルのパラメータの関係を述べる. 結果として, ゆらぎの公式は MA モデルに限らず AR や ARMA にも適用可能であることが分かる.
このゆらぎの公式を時系列モデルのパラメータ推定の良さを測る指標に応用する手法を述べると共に,時間が許せば, 具体的な時系列モデル選択の例を紹介する. なお、本研究は佐久間紀佳(愛知教育大), 長谷川彩子氏(お茶の水女子大) との共同研究の一部である.
講演者: 平野敏弘氏(日本電気株式会社 中央研究所 データサイエンス研究所,研究員)
演題: 大規模空間データに対する効率的な統計解析手法について
講演概要: 空間統計学におけるトピックの1つである大規模空間データに対する効率的な統計解析手法について紹介する.空間データ収集技術の発展に伴い,自然科学・社会科学の様々な分野において大規模な空間データに対する効率的な分析方法の必要性が高まっている.降水量や地価データといった観測地点の距離が近いほど相関が強くなるような空間データが大量に得られた場合,代表的な空間予測手法であるクリギングは異なる観測地点間の共分散行列の逆行列を含んでいるため,計算時間が非常に大きくなる.この計算負荷を軽減するためにCovariance Taperingという手法が提案されている.これは確率場の真の共分散関数とコンパクトな台を持つ相関関数の積で元の共分散関数を置換するという手法であり,置換された共分散行列は疎行列となるので高速計算が可能となる.本発表では,正規確率場のエルミート多項式で表現可能な非正規確率場におけるCovariance Taperingの性質について紹介する.また,時間があれば,別の高速計算手法であるランク削減アプローチに対する補正方法についても発表する.
講演者: 逸見昌之氏(統計数理研究所,データ科学研究系)
演題: 欠測を含むデータに対するセミパラメトリックな解析法について
講演概要: 欠測を含むデータに対する統計的な解析法については、Rubin(1976)によって、最尤法やベイズ法の枠組みで欠測メカニズムの分類がなされて以来、多くの研究が行われてきたが、特に生物(医学)統計学の分野においては、1990年代後半以降、逆確率重み付け推定法(Inverse Probability Weighting)やその発展形とも言える二重頑健推定法(Doubly Robust esimation)といった、セミパラメトリックな解析法の研究が盛んに行われている。本講演では、まず必要な範囲でセミパラメトリック推測理論の概略を紹介し、次に、特に二重頑健推定量がその理論からどのように導出されるかについて解説を行う。また、統計的因果推論の問題も、潜在的結果変数と呼ばれる概念を通して欠測データの問題と見なすことができるが、(時間が許せば)これに関して最近、共同研究として行った、平均的因果効果に対する層別二重頑健推定量についても紹介する。
講演者: 鈴木 譲氏(大阪大学 理学研究科)
演題: 相互情報量の推定と独立性検定
講演概要: 最近、確率変数X,Yが連続であっても、相互情報量の値を、確率1で正しく推定(強一致性)する方法が提案されている。一般に、X,Yの相互情報量が0であることと、両者が独立であるこは同値である。しかしながら、既存の推定量は、常に正の値をとるため、X,Yが独立であることと、0の値をとることとが一致しない。本研究では、強一致性を満足すること以外に、X,Yが独立であることと、非正の値をとる(負の値をとることもある)ことが確率1で一致するような、相互情報量の推定量を提案する。推定量は、独立である場合とそうでない場合で、BIC(Bayesian Information Criterion)の値の差をとったものである。このBICは、近年講演者によって、X,Yが有限個の値をとるとか、正規分布にしたがうとか、特定の仮定を置かないで導き出されたものである。また、提案方式に基づいて、独立性検定を行う際には、帰無仮説をシミュレートして推定量のしきい値を設定するような手間は生じない。また、サンプル数nに対して、O(n log n)の計算量で、推定が完結するので、HSIC(Hilbert SchmidtIndependence Criterion、O(n^3)の計算量)などのカーネルに基づく方法とくらべて、効率がよく、ビックデータにも適用できる。最後に、数値実験を示して、提案方式の実際面での有効性を示す。
講演者: 麻生英樹 (産業技術総合研究所)
演題: Deep Learning(深層学習)による深層表現の学習
講演概要: 生物の脳を模擬したニューラルネットワークによる学習的な情報処理方式の研究は、1940年代に端を発する長い歴史を持つが、これまでに何度かの研究の盛衰を経て、最近また、Deep Learning(深層学習)という名前で注目を浴びている。その理由の一つは、音声認識や画像認識等の課題で、従来法を大きく上回る性能を示していることにある。本講演では、ニューラルネットワークの研究の歴史を踏まえながら、Deep Learning の技術的な側面と現代的な意義について解説を行うとともに、最近の応用事例を紹介し、今後の可能性について考えたい。
講演者: 江島伸興 (大分大学医学部数学・統計学講座)
演題: 一般化線形モデルによるパス解析: 基礎と発展の可能性
講演概要: 一般化線形モデル(generalized linear model: GLM)はデータ解析で幅広く用いられる回帰モデルであり、目的変数の不確実性を表現するランダム成分、説明変数の一次結合(予測子)で表される系統成分、および系統成分と目的変数の平均を連結する連結成分の3つの概念で構成されている。この概念で捉えると、線形回帰モデル(正規分布誤差)やロジットモデルなどはGLMに含まれる。本研究では変量Xiの同時分布を因果系列の条件付分布で乗法分解し、先祖の変数が子孫の変数に与える効果を評価するためのパス解析を提案する。最初に通常の線形回帰モデルとGLMの考え方を比較し、GLMと線形回帰モデルに関するパス図の違いを説明する。次に、対数オッズおよび対数オッズ比を情報理論に基づいて解釈する。対数オッズは応答変数の異なる二つの値が持つ情報量の差(相対情報量)で、対数オッズ比は説明変数に対する相対情報量の変化量であることを示す。GLMで(拡張した)対数オッズおよび対数オッズ比を議論し、説明変数の目的変数に対する予測力測度としてのエントロピー決定係数 (Entropy Coefficient of Determination; ECD) を説明する。この決定係数はランダム成分が正規分布の場合は重相関係数の2乗で、通常の決定係数である。三番目に対数オッズ比を用いて、先祖の変数が子孫の変数に与える全効果と直接効果の評価法を提唱する。この基本評価法の結果は応答変数がカテゴリである場合は特に複雑になり、効果を要約することは結果の解釈上で有用である。平均全効果、直接効果、間接効果を計算し、ECDによって標準化する。4番目にロジットモデルを用いて、カテゴリ変数のパス解析を例示する。最後に、提案するパス解析法の応用と発展の可能性として、(i) カテゴリ変数や連続変数の混合したシステムのパス解析、(ii) 潜在変数を含む変数システムの解析、(iii) 連関関係を含むシステムの解析、(iv) 母数推定の問題、(v) 経路解析 (pathway analysis)、(vi) ECDの応用の可能性などを挙げる。
講演者: Professor Tatsuki Koyama (Vanderbilt University)
演題: Rigorous statistics for basic and clinical sciences: Experiences in the Center for Quantitative Sciences at Vanderbilt University, School of Medicine
講演概要: no abstract available
注: 数理医学セミナーと共催
Presenter: Professor Jae-kwang Kim (Iowa State University)
Title: Recent Advances in the analysis of missing data with non-ignorable missingness
Abstract: Missing data is frequently encountered in many areas of statistics. Many existing methods for handling missing data assume that the response mechanism is ignorable in the sense that the response probability depends on the variables that are always observed. When the response mechanism is non-ignorable, then the parameter estimation is more challenging and the literature is somewhat sparse.
In this lecture, some statistical issues in handling missing data with non-ignorable missingness will be discussed. We first briefly discuss non-identifiability associated with non-ignorable missingness and then discuss how to avoid such non-identifiability using instrumental variable. Once the non-identifiability is solved, several existing methods of parameter estimation will be introduced. In particular, generalized method of moment approach, pseudo likelihood approach and exponential tilting method will be introduced. An example with an exit poll data will be briefly presented.
講演者: 中矢 徹氏(大阪大学 基礎工学研究科 数理科学領域 M2)
演題: 死亡者統計データに基づく寿命推定
講演概要:
講演者: 華山宣胤氏(尚美学園大学 芸術情報学部)
演題: A study of the upper limit of human longevity based on the analysis of data for oldest old survivors and deaths in Japan
講演概要: In the field of biology, theories of aging are roughly divided into two major groups. One is consisting of damage theories and the other is consisting of program theories. According to damage theories we age because our systems break down over time. Meanwhile, in the program theories, it is considered that we age because there is an inbuilt mechanism that tells us to die. If the damage theories are true, we can survive any longer by avoiding damaging our organism. If the program theories are true, on the other hand, we cannot survive longer than the upper limit of longevity with any effort. In this study, for discussing that either the damage theories (there exist a upper limit of human longevity) or the programing theories (there does not exist such a limit) is true, data for oldest old survivors and deaths given by age and birth-period in Japan is analyzed using the extreme value theory and the extinct cohort method. From the results of fitting the binomial regression model with probabilities calculated from the generalized Pareto distribution to the data, the upper limit of human longevity is estimated from 107 to 128 years for male or from 119 to 159 years based on the data for survivors, while that is estimated infinite for some cohorts or form 108 to 262 years for male or form 117 to 165 years for female based on the data for deaths.
講演者: 紺谷幸弘氏((株)ブレインパッド)
演題: データ分析稼業の現場から
講演概要: 最近、雑誌やweb上、またはTVなどで「ビッグデータ」や「データサイエンティスト」などの言葉が取り上げられており、 ビジネスの分野におけるデータ分析への要請が高まってきています。本発表では、発表者のデータ受託分析会社での実地経験を通じて、現場で利用されているツールや手法について、 また、現場で要請される「データ分析」の役割や、それに応えるための考え方についてお話します。
講演者: 植野 剛氏(科学技術振興機構,大阪大学産業科学研究所)
演題: 統計学習に基づく強化学習へのアプローチ
講演概要: 強化学習は心理学, 神経科学, コンピュータ科学, 制御工学など複数の研究分野に起因する機械学習法の1つである. 強化学習は未知の環境に置かれたエージェントが試行錯誤を通じて得た報酬から行動方策(方策)を自律的に学習する手法である. 強化学習の特徴は環境のダイナミクスを推定することなく,得られた報酬から行動方策を直接学習することが可能な点である. したがって, 環境のダイナミクスの数理モデル化を必要せず, 環境が強い非線形性を持つ場合でも方策学習が原理的に可能である. よって, この望ましい性質により様々な実問題に応用され, 多大な成功を収めている.
一方, 強化学習の理論面に目を向けると, 強化学習法の性能評価は計算機実験など経験的に行われており, 理論的, 特に統計的な評価はあまり行われてこなかった.この要因の1つとして, 強化学習が最適制御を基礎に数理が展開されており, これまで強化学習の統計的な解釈がなされていないことが考えられる. したがって, 本研究では強化学習の統計的観点から見直し, より一般的な統計推論問題として再定式化することを目指す. そして統計学習分野で培われてきた解析手法を応用し, これまで明らかにされてこなかった強化学習の理論的な性質を解明する(もしくは,そうなるように努力する).
本発表は, 以下の3部構成で行う. 第1部では, 強化学習の概要について, これまでの応用事例を用いて紹介する. 第2部では, 強化学習の数理的な基礎である動的計画法, 並びに代表的な強化学習アルゴリズムについて紹介する. 第3部では, セミパラメトリック統計推論の立場から強化学習を見直し, これまでに得た幾つかの重要な知見について紹介する.
講演者: 杉本知之氏(弘前大学 理工学部)
演題: 中途打ち切りデータのノンパラメトリック推定論
講演概要: 生存時間データは,基点から関心のある事象を発生するまでの時間を記述したデータであるが,限られた観察期間など様々な理由から(右側)中途打ち切りを伴うことに特徴がある.標準的な生存時間データの解析のために,Kaplan-Meier推定値,ログランク検定,Cox回帰などが,広く応用されている.Cox回帰モデルは,生存時間データのいくつかの難点を克服して回帰モデルとしての有用な解決法を与え,セミパラメトリック推測論に対する歴史的成功例である.ただし,右側中途打ち切りを超えるような不完全データを伴う場合には,Cox回帰で培われた推測理論が必ずしもダイレクトに適用可能ではないことも多い.因みに,Cox回帰モデルは,帰無モデルではKaplan-Meier推定値を,2(多)標本問題ではランク検定などのノンパラメトリック法を記述する.本発表では,いくつかの右側中途打ち切りを超えるような不完全データの例を挙げ,生存時間データの解析のための推測理論や方法をどのように拡張したり,修正すべきかを議論する.この議論を簡単に,もしくは焦点を絞るため,ノンパラメトリック推定論,すなわち,Kaplan-Meier推定値の拡張から出発し,ノンパラメトリックFisher情報量が(超)高次元の3重対角行列になることに注目する.
講演者: 清水昌平氏(大阪大学 産業科学研究所)
演題: 因果構造探索に関する最近の発展: 非ガウス性の利用
講演概要: ココ
講演者: 高橋倫也氏(神戸大学 海事科学部)
演題: 極値理論入門
講演概要: 極値理論は信頼性や保険数理(アクチュアリー)などで極めて有用である.最近は地震や津波被害でその重要性が再認識された.本講演では極値理論の基礎的な話題を提供したい.
講演者: Professor Laurens de Haan(Faculty of Economics, Erasmus University Rotterdam)
演題: Estimation of the marginal expected shortfall
講演概要: Denote the loss return on the equity of a financial institution as X and that of the entire market as Y . For a given very small value of p > 0, the marginal expected shortfall (MES) is defined as E(X | Y > Q_Y (1-p)), where Q_Y (1-p) is the (1-p)-th quantile of the distribution of Y . The MES is an important factor when measuring the systemic risk of financial institutions. For a wide nonparametric class of bivariate distributions, we construct an estimator of MES and establish the asymptotic normality of the estimator when p ↓ 0, as the sample size n → ∞. Since we are in particular interested in the case p = O(1/n), we use extreme value techniques for deriving the estimator and its asymptotic behavior. The finite sample performance of the estimator and the adequacy of the limit theorem are shown in a detailedsimulation study. We also apply our method to estimate the MES of three large U.S. investmentbanks.
講演者: 中村 隆氏(統計数理研究所 データ科学研究系)
演題: 年齢・時代・世代効果を分離するコウホート分析の方法
講演概要: 同一項目についての継続調査データから、加齢の影響、時勢の影響、世代差 (それぞれ年齢効果、時代効果、世代=コウホート効果)を分離する統計的方法をコウホート分析法(あるいはAPC分析法)と呼ぶ。それぞれの効果のあり方によ・闔ミ会の変化の様相が異なり、社会変化の構造を捉えるための有力な方法である。ただし、コウホートモデルがCohort=Period-Ageという関係による識別問題を抱えており、3効果の分離は不可能とされてきた。演者は、パラメータの漸進的変化の条件を付加したベイズ型モデルを構築、赤池のベイズ型情報量規準ABIC最小化法により識別問題を克服し、様々な分野の継続調査データに適用し分析してきた。当日は、適用例をいくつか示し、識別問題の数理とその克服法であるベイズ型コウホートモデルについて解説する。また近年提案された Intrinsic Estimator (IE)についても言及する。
講演者: 白石高章氏(南山大学 情報理工学部)
演題: 多群モデルにおける多重比較法
講演概要: パラメトリック多重比較法としてよく知られ統計解析に使われる手法は,テューキー・クレーマー法,ダネット法,シェフェ法,テューキー・ウェルシュの方法,REGW(Ryan/Einot-Gabriel/Welsch)法である.ノンパラメトリック法として,スティール・ドゥワスの方法,スティールの方法,ダンの方法がよく知られている.しかしながら,残念なことに,現在も,まだ,間違った多重比較法を載せている書籍が出版されている.誤りを起こしやすい部分の解説と,従来の手法よりも良い手法を提案し解説する.閉検定手順に関しては,記号論理学を使って,正確に良い方法を論じる.まずは,著書「多群連続モデルにおける多重比較法」に載せられているテューキー・クレーマー型多重比較法に限定し講義を行う.つづいて,多群離散型として二項モデルとポアソンモデルに対する多重比較法について,連続型との違いを述べながら解説する.最後に,時間があれば,順序制約がある場合の閉検定手順について述べる.
講演者: 川野秀一氏(大阪府立大学 工学研究科)
演題: スパース学習による遺伝子・パスウェイネットワークの推定
講演概要: 生命科学において,統計的変数選択問題は,ある疾患に関連していると考えられる遺伝子を特定することに対応し,今日まで数多くの研究が行われてきた.しかしながら,例えば,がんは一つの原因遺伝子による病気ではなく,複数の遺伝子異常が多様に組み合わさった結果であり,遺伝子毎の解析ではがんの本質には到底迫れないことも同時に分かってきた.そこで,遺伝子パスウェイの情報を用いた解析手法が近年注目を集め,パスウェイと疾患との関係性を捉えるためのいくつかのモデルが提案されている.しかし,これらの従来手法では疾患と関連している遺伝子ネットワークを構築することは困難である.
本発表では,がんの多様性を特徴付ける遺伝子パスウェイを同定するために,マイクロアレイデータとパスウェイデータに基づき各遺伝子パスウェイの活性度を求め,得られた活性度に対して$L_1$型ロジスティックモデルを構築する方法を提案する.提案手法をエストロゲン受容体の高発現由来乳がん患者の判別問題に適用するとともに,関連する遺伝子ネットワークの同定およびそのシステム的理解を試みる.
講演者: 矢田和善氏(筑波大学 数学域)
演題: Extended Cross-Data-Matrix Methodology for High-Dimension, Low-Sample-Size Data
講演概要: マイクロアレイデータ等にみられるように,データの次元数が標本数よりも遥かに大きな高次元小標本(HDLSS)データが,解析対象になる場面が増えてきている.通常の多変量解析の枠組みの手法を,高次元小標本にそのまま適用することはできない.それゆえ,高次元小標本における新しい理論と方法論の構築が必要になる.Yata and Aoshima (2010,2012, JMA)やAoshima and Yata (2011, SA)等の一連の研究で,高次元小標本データが有する特徴的な幾何学的構造と漸近正規性に着目し,高次元小標本における平均ベクトル・共分散行列の推定・検定, 変数選択, 主成分分析, クラスター分析, 判別分析, 回帰分析やパスウエイ解析など様々な統計的推測に精度保証を与えるための理論と方法論を与えた.
最近, Yata and Aoshima (2011, submitted)において, Yata and Aoshima (2010, JMA)で提案したクロスデータ行列法(CDM)を漸近最適な組み合わせに基づき拡張した, 拡張クロスデータ行列法(ECDM)を提案した.本講演では, 平均ベクトルや重相関係数等の検定問題に対して, ECDMに基づく新しい検定統計量を与える.母集団分布が非正規かつHDLSSの下で,新しい検定統計量が漸近正規性を有することを示し, FDRやFWER, 検出力などに関して, 事前に設定された精度を理論的に保証するような,新しい多重検定法を提案する.
当日は, 提案手法がHDLSSの枠組みで有効であることを示し,マイクロアレイデータを用いた実解析例も報告する.本研究は青嶋教授(筑波大学)との共同研究です.
講演者: 服部 聡氏 (久留米大学 バイオ統計センター)
演題: 加速モデルの統計的推測
講演概要: 生存時間データは臨床試験等の医学研究に頻繁に現れ、試験の実施上の要請から打ち切りを伴うことに特徴がある。Cox比例ハザードモデルは生存時間データに対する標準的なセミパラメトリック回帰モデルで、医学研究に広範な応用を持つ。Cox回帰が要請する比例ハザード性は実際のデータ解析の場面では必ずしも成り立たず、加速モデルなどの比例ハザード性を要請しないモデルのセミパラメトリック推測が発展してきた。加速モデルは線形回帰モデルに他ならないが、打ち切りの存在下では推測に困難が伴い、興味深い方法が導入されてきた。本発表では加速モデルの統計的推測の発展を概観し、モデル誤特定下での加速モデルの推測の妥当性に関する検討結果を議論する。
講演者: 福水健次氏 (統計数理研究所 モデリング研究系)
演題: カーネルベイズルール: 正定値カーネルによるベイズ推論
講演概要: カーネル法の新たな展開として,ベイズルールを制定地カーネルによって記述する方法を提案する.正定値カーネル及びそれの定める再生核ヒルベルト空間を用いたデータ解析の方法論である「カーネル法」では,データないしは確率変数を標準的方法で高次元の関数空間(再生核ヒルベルト空間)に写像することによって,データの非線形性や高次統計量を取り出す.再生核ヒルベルト空間の特殊な内積のおかげで,さまざまな古典的データ解析手法を容易に非線形拡張することが可能であり,かつ,計算量がサンプルサイズの行列計算に還元される点に長所がある.近年,再生核ヒルベルト空間に写像された確率変数の平均によって分布を表現することにより,二標本検定や独立性検定といった,分布に関するノンパラメトリックな統計的推論が可能となることが明らかとなってきた.本講演では,このアイデアをベイズ推論に発展させる.すなわち,事後確率の再生核ヒルベルト空間における平均を,事前確率と条件付き確率の再生核ヒルベルト空間における表現を用いて求める方法を導く.この方法では,事前確率 \pi(x)と条件付き確率 p(y|x)に関する情報が,それぞれ \pi とp(x,y) に従うサンプルによって与えられれば十分であり,事前確率や条件付き確率の陽な式は必要でない点に特徴がある.事後確率の再生核ヒルベルト値平均は,x のサンプルの重み付き和として与えられる.このカーネルベイズルールに基づいて,さまざまなベイズ推論の方法をノンパラメトリックに拡張する方法を述べる.
講演者: 田中研太郎氏 (東京工業大学 社会理工学研究科)
演題: 線形構造方程式モデルにおける介入とその最適化
講演概要: 線形構造方程式モデルにおいて, 介入によって最終的な出力の分散を最小化する問題を考える. この問題についてこれまでに研究されていた方法では, 介入方式への制限を特に考慮に入れていなかったため, 最適な介入方式が実際には実行不可能な場合に達成されてしまう可能性があった. そこで, 今回の研究発表では, 最適な介入方式を決定する問題を凸二次計画問題として定式化して解く方法について紹介する. また, 得られた最適解の解析において, 総合効果の概念が非常に有用であることについても紹介する. これらのことについて説明した後で, 潜在変数がある場合への拡張についての考察を述べる.
講演者: 井元清哉氏 (東京大学 医科学研究所)
演題: がんの多様性解明を目指したシステム解析アプローチ
講演概要: がんはゲノム上に生じた複数の変異が複雑に組み合わさった結果であると言われています。1990年代初めに国際ヒトゲノム計画がスタートし、13年あまりの時間をかけてヒトゲノムが決定されました。ヒトゲノムの全塩基配列30億文字を決定することは一昔前には多数の国が多大な費用を費やし行う国際プロジェクトでした。しかしながら、生命科学におけるデータ計測技術の進歩はめざましく、現在では一人のヒトゲノムを数日で読むことが可能となりました。これは、すなわち個人ゲノム時代が幕を開けたことを意味します。この高速シークエンサーを武器に、国際がんゲノムコンソーシアムがスタートしました。日本においては、肝臓がん500検体、同一患者からの正常肝臓細胞500検体のゲノムを読むことになっています。これらのデータから、がんの多様性が明らかになることが期待されています。このような技術革新、問題背景の元、本講演では、がんの多様性を明らかにすることを目標として、計測された生命科学のデータから細胞内の分子ネットワークを推定する方法を紹介します。また、生体内分子ネットワークの違いからがんの多様性に関わる鍵分子、パスウェイの同定について論じます。
演題: 調査会社の現況
講演者: 森本栄一氏((株)ビデオリサーチ)
演題: 傾向スコアによるインターネット調査補正の実用化
講演者: 庄野 宏氏((独)水産総合研究センター)
演題: 傾向スコアによるまぐろ類の漁獲効率解析の補正の試み
講演概要: 本発表では、傾向スコアによる補正をまき網で漁獲される代表的な熱帯性まぐろ類の漁獲効率解析へ適用し、漁業者の感覚と異なる結果が得られていた、まき網の目合いを変更した場合の小型魚の漁獲削減効果について検討する。具体的には、2002-2007年におけるまぐろ類(中西部太平洋のメバチ・キハダ・カツオ)の漁獲データを利用し、これら3種類の漁獲の有無や漁獲割合、漁獲重量が、まき網の目合いを大きくした場合に漁獲効率が削減されるか否かについて、傾向スコアを共変量として組み込んだ一般化線形モデル、およびH-T type推定量(2群の比較に際して傾向スコアを用いる方法)等により解析した。
Speaker: Professor Milan Studeny(Academy of Sciences of Czech Republic)
Title: On testing conditional independence implication
Abstract: Formal properties of probabilistic conditional independence (CI) and attempts to describe probabilistic CI inference in terms of mathematical logic have been traditional research topics since the late 1970's. In the beginning, I plan to recall a little bit of history of CI inference. The main topic of the talk will be our attempts at computer testing of probabilistic CI implications by an algebraic method of structural imsets. The basic idea is to transform (sets of) CI statements into certain integral vectors and to verify by a computer the corresponding algebraic relation between the vectors. The previous methods for computer testing of this algebraic implication will be interpreted from the point of view of polyhedral geometry. Then the idea of a new method, based on linear programming, will be explained. The new method overcomes the limitation of former methods to the number of involved variables. In the eTitle: nd, our computational experiments, whose aim was to compare the efficiency of the algorithms, will be outlined. The experiments show that the linear programming method is clearly the fastest one.
The talk will report on joint research with Raymond Hemmecke (TU Munich, Germany), Remco Bouckaert (University of Waikato, NZ) and Silvia Lindner (University of Magdeburg).
講演者: 宮田 敏氏(財団法人 癌研究会)
演題: 適応型モデル選択基準を用いた確率モデルの推定
講演概要: 回帰分析,判別分析あるいは確率密度推定などあらゆる統計的モデリングにおいては,チューニングパラメタの最適化によるモデル選択が重要な問題となる.本研究では,各種のノンパラメトリック統計モデルに対して,適応型モデル選択基準(Adaptive Model Selection Criterion, AMSC)を用いたモデル選択の手法について紹介する.AMSCは元々指数型分布族に対するモデル選択基準として導入され,Kullback-Leibler損失の平均二乗誤差の意味での最良の推定量として定式化される.一般にパラメタに関するモデル選択基準の最適化は複雑な非線型問題となるが,本研究では遺伝的アルゴリズムを用いた大域的な最適化を提案する.
非線型回帰モデルや確率密度推定などに対して従来用いられてきたノンパラメトリックモデルでは,推定対象の変数間の確率的構造に「滑らかさ」を仮定し,カーネル関数などを用いたモデル化が行われてきた.しかし実際に統計モデルが応用される経済あるいは生物関連などのデータには,不連続なジャンプや鋭いピークなど「滑らかでない」現象がしばしば観察される.本研究では,適応型可変節点スプライン (Adaptive Free Knot Spline, AFKS) を用い,目的関数(回帰関数,確率密度関数, etc.)が微分不能な点や不連続点を持つような場合も含め,出来る限り一般的な状況でのモデル選択問題を考察する.
講演者: 樋口知之氏(統計数理研究所 モデリング研究系 時空間モデリンググループ)
演題: 階層ベイズモデルにおけるディリクレ混合過程と粒子フィルタ
講演概要: 一般に共通する知識の獲得と個性・状況の表現といった、通常相反する目的の達成を目論む、つまり二兎を追うのが階層ベイズモデルの利用である。通信インフラの整備や計測技術の進歩は、データの個性・状況への依存度をさらに加速し、それにともないベイズモデルの高層化は増す一方である。ノンパラメトリックベイズと呼ばれる、データ一つ一つにハイパーパラメータを指定するモデルもその一つの例である。あまりにも柔軟で複雑なモデルを使いこなすためには、当然、MCMCや逐次MC(粒子フィルタ)といった類の数値的アプローチ(ベイズシミュレーション)を採用せざるを得ないが、問題に即した合理的な事前分布の設定を数値的に実現する作業も本質的である。ディリクレ混合過程の採用はその線に沿ったアイデアと言える。アルゴリズムの外形的な特徴、また更新プロセスがもたらす実体的効果を考えると、このディリクレ混合過程と粒子フィルタはほぼ同一であることはあまり意識されていない。本講演ではこの両者を俯瞰するとともに、先進的計算機環境に即した粒子フィルタアルゴリズムの研究動向についても触れたい。
Presenter: Professor Soonmook Lee(Sungkyunkwan University, Republic of Korea)
Title: Examination of Two Approaches to Identification Problems in Analysis of Single Indicator MTMM Data
Abstract: It has been widely recognized that confirmatory factor analysis(CFA) approach to specifying method factors suffer empirical nonidentifications in analyzing covariance structure of multitrait-multimethod(MTMM) data with single indicators. Two approaches were identified as a potential remedy of the problem. One is based on the idea of Williams(2007) introducing a (spurious) mean structure to the CFA model, supplying more information to the estimation process. Another is to introduce a random intercept factor that is orthogonal to the factors in the current CFA model (Maydeu-Olivares & Coffman, 2006), consuming more information in the estimation process. Rationale and effectiveness of these two contrasting approaches will be examined with simulated data and empirical data.
Keywords: confirmatory factor analysis, MTMM, identification, method factor
Speaker: Professor Vladimir Ulyanov(Moscow State University, Faculty of Computational Mathematics and Cybernetics)
Title 1: Berry-Esseen type limit theorems in probability and statistics
Abstract: In this talk I give review on recent results of different authors about Berry-Esseen type limit theorems and also my own recent results in this direction.
Title 2: Asymptotic properties of almost quadratic forms
Abstract: We study approximation for power-divergence family of statistics which includes in particular traditional goodness-of-fit tests: Pearson's chi-square test, loglikelihood ratio statistic and Freeman-Tukey statistic. We get rate of convergence to chi-square distribution reducing the original problem to problem of approximation of number of lattice points in large convex bodies.The talk consists of two parts: at first we consider approximation for Pearson's chi-square test. It leads to classical problem in number theory about number of integer points in ellipsoids. The second part is devoted to other statistics whose distribution functions could be represented as probabilities that normed sums of independent integer valued random vectors hit convex sets which are "similar" to ellipsoids. In this case it is necessary to apply number theoretic results obtained just recently.
Presenter: Professor Sik-Yum Lee(The Chinese University of Hong Kong, Department of Statistics)
Title: A two-level structural equation model approach for analyzing multivariate longitudinal responses
Abstract: The analysis of longitudinal data to study changes in variables measured repeatedly over time has received considerable attention in many fields. This paper proposes a two-level structural equation model for analyzing multivariate longitudinal responses that are mixed continuous and ordered categorical variables. The first level model is defined for measures taken at each time point nested within individuals for investigating their characteristics that are changed with time. The second level is defined for individuals to assess their characteristics that are invariant with time. The proposed model accommodates fixed covariates, nonlinear terms of the latent variables, and missing data. A maximum likelihood approach is developed for estimation of parameters and model comparison. Results of a simulation study indicate that the performance of the maximum likelihood estimation is satisfactory. The proposed methodology is applied to a longitudinal study concerning cocaine use.
Keywords: Latent variables, longitudinal study on cocaine use, MCEM algorithm, model comparison.
講演者: 柳原宏和氏 (広島大学)
演題: A non-iterative optimization of smoothness in penalized smoothing spline
講演概要: スプライン平滑化は,複雑なトレンドを持つデータに対して,単純にかつ短い計算時間で平滑化結果を得ることができる手法である.推定曲線の局所変動の程度を制御する平滑化パラメータは選択には,情報量規準が用いられることが多い.しかしながら,情報量規準により平滑化パラメータの最適化を行った場合,最適な平滑化パラメータを得るためには計算機による繰り返し計算が必要となり,基底関数の最大個数が多くなるほど計算量も膨大となる.そこで本報告では,一般化リッジ回帰モデルにおけるリッジパラメータの最適化法を応用することにより,最適な平滑化パラメータを繰り返し計算無しに求める方法を提案する.最適な平滑化パラメータは,予測値の平均二乗誤差に基づくリスクの推定量となる情報量規準の最小化により求められる.さらに,選ばれた平滑化パラメータを確率変数とみなし,基底関数決定のための新たな情報量規準も提案する.
講演者: 藤越康祝氏 (中央大学大学院理工学研究科)
演題: 高次元データの推測における最近の発展と展望
講演概要: 最近, 変数の数pが標本の数nより大きいデータに対して, 高次元枠組での漸近理論に基づく推測法が発展し, DNAデータなどにも適応されている. 一般に, 高次元というと, (1) 「p >> n」を想定するが, この報告では, (2) 「p < n かつ, p も大きい」場合も含めて考える. 高次元になると, 伝統的多変量手法が利用できなくなったり, また, たとえ利用できたとしても, 方法とし役立つものなのかという疑問が生じる. 一方では, 高次元特有の手法を開発したり, それらの高次元枠組での漸近的性質を明らかにすることが重要になる. さらに, 多変量解析では, 解析の目的に対して情報をあまり失わないで, できるだけ次元や変数自体を減らして分析することが重要であるが, この問題は, 高次元になるとますます重要になるということは言うまでもないことであろう. 一般に, 通常の多変量データ分析において, 変数の数が増えると, 大標本近似に基ずく手法は利用できなく, 高次元近似に基ずく手法に修正する必要がある. そのような手法は大標本の状況に対しても利用できるであろうか. 本報告では, 主として, 主成分と判別に焦点を当てて, 上記に関連した主要な成果を紹介しながら, 展望を試みる.
講演者: 栗木 哲氏 (統計数理研究所)
演題1: 非心ウィシャート分布のモーメントのグラフ表現とその応用
講演概要: 実, 複素非心ウィシャート行列のモーメントの一般形を (それぞれ) 無向, 有向グラフの言葉で表現する. その系として, 2変量ガンマ分布, 2×2中心ウィシャート行列の一般次数モーメントをグラフの数え上げによって与える. またラゲール多項式が, 形式的に負の非心度を持つ非心カイ2乗分布のモーメントと解釈できることを用いて, ラゲール多項式の係数の組合せ論的解釈を与える.
演題2: 遺伝子座間の相互作用による生殖的隔離障壁の検出と多重性調整
講演概要: 種を分ける遺伝的しくみである生殖的隔離は,遺伝子座間の相互作用によってもたらされると考えられている.ここでは,密なマーカー遺伝子座の総当たりを行い2遺伝子座間の「分離のゆがみ」をとらえることによって,生殖的隔離機構の検出を試みる.検定の総数が膨大となるため,多重性の調整が必要となる.連鎖が引き起こす確率構造を同定すると,多重検定はカイ2乗確率場ととらえることができる.その確率場の最大値の分布を非線形再生理論およびチューブ法によって近似することにより多重性調整が可能であることを報告する.
講演者: 松井茂之氏 (統計数理研究所)
演題: ランダム化臨床試験での再発事象のセミパラメトリック解析
講演概要: 医薬品などの治療法の効果は最終的には臨床上のイベントを対象としたランダム化臨床試験によって評価することが求められる.臨床イベントとして,感染症,喘息やてんかん発作,表在性腫瘍の再発といった同一個体上に繰り返し起こる再発事象(recurrent events, repeated events)を扱う場合には特別な配慮が必要である.臨床での再発事象は,個体内で複雑な相関構造をもち,発生頻度や発生パターンの個体差も大きい.これらを患者背景や診断情報などの共変量によって説明するのは難しい.その一方で,ランダム化臨床試験では,そもそも治療効果に興味があり,個体内相関や個体差は局外因子とみなされる.本講演では,事象系列を完全に特定しないセミパラメトリックな解析について紹介し,ランダム化臨床試験における有用性について考える.
講演者: 川喜田雅則氏 (九州大学)
演題: 情報幾何によるブースティングの性能の考察
講演概要: ブースティング法を予測分布構成法とみなしたときの性能の解析を行う。結果として弱学習機モデルが真の分布を含むとき、ブースティングを行うことで性能が悪化する方向へ分布をシフトすることを示す。またこのときのシフトは大雑把に言えばkomaki(1996)で示された最適なシフトとちょうど同じ良だけ反対の方向になることがわかる。また余裕があればブースティングとカーネルマシンの関係についても言及する。
講演者: 林 賢一氏< (大阪大学D3)
演題: ミスラベル確率の推定のためのブースティング
講演概要: 二値判別問題において,観測されたラベルが必ずしも真でないと考えられる場合が存在する.この場合,ラベルが全て真であると仮定している通常の判別手法は,予測性能が悪くなり,誤った結論を導く可能性を孕んでいる.従って,ミスラベルが起こる確率をモデリングした下で判別を行うことが要請される.ブースティングなどの機械学習における方法論では,ミスラベル確率を推定する方法は確立されていない.適当なチューニングパラメータとして事前に与えることも考えられるが,当然それらの値により結果は変わる.また,一般には真のラベルは観測されないので,クロスヴァリデーションなどを用いてパラメータを決定することも困難である.
本発表では,ミスラベル確率を規定するパラメータの推定方法について考察する.発表者が提案する,非対称ミスラベルデータに対するブースティングでは判別函数を構成した後で,一定の制約下でミスラベル確率が推定できることを数値実験により示す.
講演者: 内藤貫太氏 (島根大学)
演題: On the Use of Maximal Dilatation in Multivariate Analysis
講演概要: 対応のある多変量データについて、その類似性について考える。このような類似性を測る尺度して最大歪曲度(Maximal Dilatation)を用いることを提案する。最大歪曲度は擬等角写像の理論において現れ、等角写像からの乖離を測るものである。完全な類似を“調和”と捉え、調和からのずれを等角写像からのずれと定式化することで、最大歪曲度を統計解析に用いることができることを示す。ある設定の下では、最大歪曲度の計算は、Procrustes Statisticsと同値になることが示される。Linear MappingとRadial Mappingを用いた場合の最大歪曲度の挙動を考察し、実データへの応用を紹介する。
講演者: 松井知子氏 (統計数理研究所)
演題: グラフカーネルによる画像の概念抽出-- 画像の幾何学的特徴の利用 --
講演概要: 近年、映像索引付け・検索技術に関する国際的な競争型評価プロジェクトTRECVIDなどで、映像検索の要素技術として、ある画像に特定の概念が含まれているかどうかを判定する、画像の概念抽出法に関する研究が盛んに行われている。本講演では、画像の幾何学的特徴を捉えるためにグラフカーネルを用いる方法について紹介する。本方法では、画像を自動的にセグメント化し、セグメントをグラフの頂点として、隣接するセグメント間を辺として扱い、画像中の各セグメントの隣接関係をグラフとして表現する。なお、各セグメント(つまり頂点)は、その画像特徴量(色やテクスチャ情報など)で表わす。次に、グラフ表現した画像間の類似度を表すグラフカーネルを定義する。101個の概念を対象とするベンチマーク・データで評価したところ、このグラフカーネルとサポートベクターマシンを組合せて用いることにより、従来法と比べて概念抽出の制度を50%以上向上できることがわかった。
講演者: 坂本 亘氏 (大阪大学)
演題: メタボ診断基準の問題に見る,統計的データ解析が果たす役割
講演概要: 肥満症診断基準検討委員会と日本肥満学会による論文 (Circulation Journal,66, 987-992, 2002)(以下,検討委論文)は肥満症の診断基準として男性85cm,女性90cmという胴囲分割値を定めた.これは日本人のメタボリック・シンドロームの診断基準の論拠ともなっている.ところが,この検討委論文には統計的側面での様々な問題点が存在する.坂本 他 (行動計量学,35, 177-192, 2008) は,検討委論文の記述内容に基づいて再解析を行い,その結果,データの収集と解析をやり直すことで診断基準が変わる可能性が高いことを確認した.このような不適切な診断基準が導かれた原因は検討委論文が統計の基礎をおろそかにしたことにある.本講演では,検討委論文を題材に,データ収集の計画,データの種類や構造に即した解析手法の選択,交絡因子による層別など,統計的データ解析を過程として捉えることの重要性を例示する.さらに,論文等に記載されている要約統計量の値などをもとに,元のデータの生成過程をシミュレーションにより再現する方法も概説する.
講演者: 青山和裕氏 (愛知教育大学)
演題: 初等・中等段階における日本の統計教育の現状と課題,今後の方向性
講演概要: 昨年度の学習指導要領改訂により小学校,中学校,高等学校での確率・統計に関する指導内容が大幅に充実する見通しとなった。世界的には初等・中等段階での統計教育改善は1980年代から取り組まれており,日本は実に20年以上もの遅れを取りながら,これから取り組んでいくこととなる。 本講演では,1)日本の統計教育に関する歴史的経緯,2)諸外国での統計教育改善の動向,3)これから着手する日本の統計教育改善の方向性の3つの内容について取り上げる。特に3)については,日本統計学会において進行中の各種統計学習支援プロジェクトについてもふれ,これから日本で実施される統計教育に関する具体的内容等についても紹介する。
講演者: 西山慶彦氏 (京都大学)
演題: A nonparametric test for the existence of moments
講演概要: In many statistical procedures, the existence of moments of certain order is required. For example, laws of large numbers require the existence of mean, and central limit theorems entail the existence of variance. They play essential roles in proving the consistency of estimators and hypothesis testing respectively. In the case of fully parametric approach, specified models determine if moments of some order exist or not, possibly depending on the parameter values. If the existence depends on the parameter values, as in, say, Pareto distribution, t distribution and many more, we will be able to test for the existence of moments using the parameter estimates. Obviously, the correct specification is essential there. To the best of our knowledge, however, there is no test for the existence of moments proposed before in nonparametric framework. The present paper proposes a nonparametric test for the existence of moments. We consider a class of distributions in which the characteristic function is differentiable as many times as one wishes except the origin. It is, we believe, a sufficiently broad class in empirical applications, which is characterized using the theory of hyperfunctions. We use the estimates of left (and right) limit(s) of the first two derivatives of the characteristic function to construct the test statistics. We examine the property by some Monte Carlo simulation.
講演者: 杉山 将氏(東京工業大学 計算工学専攻)
演題: 確率密度比の直接推定とその機械学習への応用
講演概要: 確率密度関数の推定は統計的機械学習における最も難しい問題の一つとして認識されており,何らかの学習問題を解く際に確率密度の推定を避けることは精度のよい学習結果を得るために非常に重要である.このような考え方は「Vapnikの原理」としても知られており,精度の良いパターン認識手法として知られているサポートベクターマシンはこの原理に従っている.
本講演では,我々が最近導入した新しい統計的機械学習の枠組みを紹介する.この枠組みの特徴は,様々な機械学習問題を確率密度関数の比の推定問題に帰着させるところにあり,確率密度推定を経由せずに密度比を直接推定することにより,Vapnikの原理に従う良質な学習結果が得られる.この密度比を用いる枠組みには,非定常環境適応,ドメイン適応,マルチタスク学習,外れ値検出,時系列の変化点検知,特徴選択,次元削減,独立成分分析,条件付き確率推定,二標本検定など様々な機械学習の問題が含まれるため,極めて汎用的である.
密度比推定の代表的な手法の原理を解説するとともに,ブレインコンピュータインターフェイス,ロボット制御などへの応用例も紹介する.
参考文献:
杉山 将. 非定常環境下での教師付き学習: データの入力分布が変化する場合. 画像ラボ, vol.18, no.10, pp.1-6, 2007.
Quinonero-Candela, J., Sugiyama, M., Schwaighofer, A., & Lawrence, N. D. (Eds.), Dataset Shift in Machine Learning, MIT Press, Cambridge, 2008 (in press).
講演者: 林 賢一氏(大阪大学 基礎工学研究科 数理科学領域 D2)
演題: Boosting method for asymmetric mislabeled data
講演概要: The boosting method when observed binary labels may not be true is considered. There is the case that observed labels in training data may be inverted by error, e.g., doctor's misdiagnosis. Doctors may diagnose a healty man as being sick and vice virsa. We propose a boosting method for "Asymmetric mislabeled" data, which is a generalized but natural idea of mislabeling; mislabelling probability depends on the true label. For example, consider the question "Do you have an official job offer after your graduation?" to university students. Students who have that will answer "yes" honestly. However students who have not any official job offer may tell a lie. Such an "asymmetric mislabeled" situation is found on research studies related to private affairs.
講演者: 谷崎久志氏(神戸大学 大学院経済学研究科)
演題1: Volatility Transmission between Japan, UK and USA in Daily Stock Returns
講演概要: In the past, there are a lot of studies which conclude that the holiday, asymmetry and day-of-the-week effects influence stock price volatility. Most of the studies are based on a class of GARCH (Generalized Auto-Regressive Conditional Heteroskedasticity) models. No one examines these effects simultaneously using SV (Stochastic Volatility) models. In this paper, using the SV model, we examine whether these effects play an important role in stock price volatilities. Furthermore, we consider spillover effects between Japan, U.K. and U.S., where spillover effects in price level as well as volatility are taken into account.
演題2: A Simple Gamma Random Number Generator for Arbitrary Shape Parameters
講演概要: In the past, a lot of gamma random number generators have been proposed, and depending on a shape parameter (say, $\alpha$) they are roughly classified into two cases: $0<\alpha< 1$ and $\alpha > 1$ ($\alpha=1$ might be included in either of the two cases). In addition, Cheng and Feast (1980) extended the gamma random number generator in the case of $\alpha>1/n$, where $n$ denotes an arbitrary positive number. Taking $n$ as a decreasing function of $\alpha$, in this paper we propose a simple gamma random number generator with shape parameter $\alpha>0$. The ratio-of-uniforms method is utilized as a sampling method, where the acceptance rate of the proposed generator is almost constant (i.e., about 0.76) for a wide range of $\alpha$ and it takes a minimum value (i.e., 0.5) at $\alpha=0$. The proposed algorithm is very simple and shows a good performance.
講演者: 鈴木 譲氏(大阪大学 大学院理学研究科)
演題: 一致性を満足した上で最も複雑なモデルを選択する情報量基準
講演概要: 属性値のもとでのクラスの条件付確率を推定するモデル選択で、AICやBICなどの情報量基準を使いたい。一致性を満足した上で最も複雑なモデルを選択したい場合、(条件付確率の推定ではなく)ARMAでは、重複対数の公式を用いた情報量基準Hannan and Quinnが提案されている。本講演では、条件付確率の推定に対しても類似の情報量基準が得られるということをKolmogorovの重複対数の公式を用いて証明する。また、Bayesianネットワークの構造学習への応用について示唆する。
講演者: 加藤 剛氏(防衛大学校)
演題: 時系列モデル化とMCMCによる先物商品のリスク評価
講演概要: 先物取引とは,価格が変動する商品について,現物の受け渡しは数ヶ月先に実行することとして,売買の約定を結ぶ取引のことである.対義語が現物取引で,これは,売買契約の成立と同時または数日後に現品の受渡しを行う取引である.
先物取引を行いたい場合,通常は取引業者(商品取引所の会員)に証拠金と呼ばれる担保を預け,取引を委託する.売買を行う過程で計算上の損失が一定額以上になった場合,委託者が取引を継続する場合は,追証拠金(新たな担保)を取引業者に支払わなければならない.取引を精算(決済)する場合は,追証拠金を負担する必要はない.損失が生じた状態で委託者が決済を行った場合,取引業者はその損失を負う.したがって,約定値が将来どの程度変動して,どの程度の損失を被る可能性があるかを予測することは,取引業者にとって切実な問題である.
約定値に関する先行研究は,収益率に換算したデータをARCHモデル等によって行うものが多いが,このモデル化では,約定値の価格決定に重要な役割を果たす値幅制限という仕組みを無視することになる.本講演では,回帰モデルの一種であるトービットモデルを導入することによって値幅制限の仕組みを忠実に反映させ,収益率に換算しない約定値データそのものを時系列モデル化する.そして,マルコフ連鎖モンテカルロ法を利用してモデルの未知パラメータを推定し,約定値の将来の確率分布を算出する方法を紹介する.
講演者: 前園宜彦氏(九州大学 大学院数理学研究院)
演題: Hoeffding 分解と漸近展開への応用
講演概要: 条件付期待値を利用した Hoeffding 分解を紹介し、その漸近理論への応用について講演する。条件付期待値を使って、独立同一分布にしたがう確率変数の和の近似を求め、漸近正規性を示す方法は、基本的な道具として順位統計量などに適用されてきた。Hoeffding 分解はこれをさらに高次の近似まで拡張したものになっている。この分解はフォワードマルチンゲールの和になっており、マルチンゲールのモーメント評価を利用することにより、統計量の近似の理論的な評価を求めることができる。またモーメント評価とマルコフの不等式を利用して、統計量のエッジワース展開を求めるときにも有用な方法になっている。Hoeffding 分解は U-統計量について導入されたが、他の統計量にも応用可能である。比の形の統計量について報告し、フィッシャーのz-変換・フ拡張についても議論する。なおこの講演では、モーメントの存在条件を仮 定するだけで、分布は特定しない。
講演者: 西井龍映氏 (九州大学 大学院数理学研究院)
演題: Contextual classification and unmixing of geospatial data based on Markov random fields (マルコフ確率場に基づく空間データの空間情報を用いた判別と分解)
講演概要: In supervised and unsupervised image classification, it is known that contextual classification methods based on Markov random fields (MRF) improve non-contextual classifiers significantly. In this talk, we consider contextual supervised classification based on MRF. Further, unsupervised unmixing problem is discussed by introducing a new MRF. The proposed methods were successfully applied to a synthetic data set and benchmark data sets for classification.
講演者: 青木 敏氏 (鹿児島大学理学部 数理情報科学科)
演題: 計算代数統計の発端と展開
講演概要: 計算代数統計(computational algebraic statistics)は,近年急速に注目を集め発展してきた分野である.計算代数統計では,統計学で用いられる多くのモデルが連立多項方程式系の解集合の部分集合として特徴付けられることに注目し,これらのモデルを代数的なツールを用いて研究する.この観点は統計的モデリング全般に広くかかわる新しいものであるといえる.計算代数統計が注目されるようになったもう一つの背景としては,計算機の発達とともに,代数学が実際に計算できる分野へと変貌をとげつつある,という事実がある.この計算代数の技術的な基盤をなしているのは,グレブナー基底の理論に基づくさまざまな代数アルゴリズムであり,小規模なデータであれば,さまざまなソフトウェアを動かして,直ちに結果を確かめることができることは,この分野の大きな魅力のひとつである.本セミナーでは,計算代数統計が発達する発端となった問題のひとつである,分割表の検定問題に対する代数的解法と,それに関連した講演者の最近の研究成果を紹介する.なお,紹介する結果の多くは,東京大学の竹村彰通教授との共同研究である.
講演者: 高井啓二氏(大阪大学 基礎工学研究科数理科学領域D3)
演題: 無視可能な欠測のある場合のAIC
講演概要: 本発表では,無視可能な欠測があるときの情報量規準について考察する.欠測値のあるデータ解析のデファクトスタンダードである「無視可能な欠測メカニズム」はRubin(1973)やLittle and Rubin(2002)の枠組みで定義されている.しかし,彼らの枠組みに基づいて作られたAICは現在までのところ提唱されていない.欠測値のデータ解析が彼らの枠組みで考えられている現状を鑑みると,AICも同様に彼らの枠組みに基づいて考えるべきである.本発表では,導出の考え方の一私案を紹介する.また他の無視可能な欠測があるときのAICとの数値的比較も行う.
講演者: 二宮嘉行氏(九州大学 大学院数理学研究院)
演題: 因子分析モデルにおける局所錘型母数化およびそのモデル選択への応用
講演概要: 因子分析における因子数選択問題を扱うため,帰無モデルおよび対立モデルの因子数をそれぞれ m および m+1とした尤度比検定を考える.因子分析モデルは識別不能性をもっており,その検定統計量の帰無仮説のもとでの漸近分布はカイ二乗分布とならない.本講演ではDacunha-Castelle and Gassiat (1999)によって導入された局所錐型母数化の方法を拡張し,その漸近分布を評価する.また,その結果を用いて識別不能性を考慮した AIC を導き,形式的なAIC より妥当な因子数選択を与えることを数値実験により示す (広島大学・柳原宏和氏,Notre Dame 大学・Ke-Hai Yuan 氏との共同研究)・D
講演者: 室井芳史氏(大阪大学 金融保険教育研究センター)
演題: Brown運動と微分・積分
講演概要: 数理ファイナンスを学ぶにあたり確率解析は欠くことのできない道具となった。本発表では、直感的にブラウン運動の構築を行い、近年の数理ファイナンスの話題まで案内することを目標とする。まず、ブラウン運動の話しをする前に、ランダムウォークについて言及し、そのアナロジーから徐々にブラウン運動や確率解析の話題について話をしていきたいと思う。その上で、(ブラウン運動の)伊藤公式の理解を目指したい。一方、数理ファイナンスのオプション価格モデルにおいて、オプションのある特定のパラメータの感度を知ることは、リスク管理の基本である。ブラック・ショールズ式の導出と平行してデルタなどのヘッジ・パラメータを計算することについても考えてみたい。最終的には、ブラウン運動の関数の微分積分の構築法と、それを用いたヘッジ・パラメータの計算方法について考察を行う。
講演者: 鷲尾 隆氏(大阪大学 産業科学研究所)
演題: Complete Split Graph列挙に基づく高精度PSD推定手法
講演概要: PSD行列のComplete Split Graphに対応する既知要素から他の未知要素を推定する手法をPSD推定手法を紹介する。更に、同じく複数のComplete Split Graphの重ね合わせに対応する 既知要素から、より高精度に未知要素を推定する手法も紹介する。
講演者: 猪口明博氏(大阪大学 産業科学研究所)
演題: グラフ系列からの頻出変化パターンの高速列挙法
講演概要: 人間関係,ホームページのリンク構造,遺伝子ネットワークなどはグラフを用いてあらわすことができる.またそれらのグラフ(ネットワーク)は,時間の経過とともに構造変化する.本講演では,そのような変化するグラフ系列データを扱うため,グラフ変更操作オペレータ,和グラフを定義し,そのようなグラフ系列データから特徴的な部分構造の変化を効率よく列挙する方法を紹介する.
Speaker: Professor Sik-Yum Lee(the Chinese University of Hong Kong)
Title: Bayesian Methods in Estimation and Model Comparison of Structural Equation Models
Abstract: Bayesian methods have been widely appreciated in analyzing complicated statistical models in various fields. In this talk, applications of these methods in analyzing structural equation models will be discussed. Basic ideas in applying the data augmentation, Gibbs Sampler, and path sampling to achieve the Bayesian estimates of the parameters and the Bayes factor for model comparison will be presented. The methodology will be illustrated through an example with real-life data.
講演者: 兼清道雄氏 (エーザイ株式会社)
演題: 試験統計家の道
講演概要: 「ICH E9 臨床試験のための統計的原則」において,「試験統計家」は『本ガイドライン中の原則を実行するために,十分な理論又は実地の教育及び経験を併せ持ち,かつ当該試験の統計的側面に責任を持つ統計家』として定義されている。製薬会社に勤めて間もない講演者が,自身の学生時代を振り返りつつ,現在,携わっている業務とそのつながりについてざっくばらんに紹介する。ICH E9 臨床試験のための統計的原則@PMDA
講演者: 村山香織氏 (キヤノン株式会社)
演題: 企業と大学の研究の違いと就職活動の指針
講演概要: 本講演では、現在の仕事の紹介と自分の就職活動の内容を通して、皆さんが希望の進路を決定し、希望の職種に就くためのヒントになることを目指します。講演ではまず、企業(特にメーカー)の研究職と大学の研究との違いについてご説明します。そして、就職活動の進め方、企業において求められる人材(=面接で通る人)についての見解を述べたいと思います。
講演者: 中村和幸氏 (統計数理研究所)
演題: データ同化手法と津波シミュレーションモデルへの適用について
講演概要: 津波シミュレーションモデルに対するデータ同化手法の適用を通じて,その問題点等について議論するとともに,実際のデータを用いた解析の結果について述べる.データ同化とは,数万次元程度の大規模な数値物理シミュレーションモデルと,観測データの両方をなるべく満足するよう修正する手法のことであり,シミュレーションの精度向上や知識発見,よりよいシミュレーションモデルの構築等を目的とする手法である.従来,気象学・海洋学を中心とした地球物理学の分野で発展してきた手法であるが,現在は様々な数値シミュレーションを用いる場面で使用されてきている.本発表においてはまず,データ同化の目的と従来から用いられてきた手法について,時系列解析を中心とした統計手法の観点からの意味づけを与える.ついで,津波シミュレーションモデルへの適用を主な例としながら,データ同化のためのモデリング,すなわち物理シミュレーションモデルを使う際のモデリングにつ・「て議論を行う.これにより,非線形非ガウス型状態空間モデルが構成されることとなり,粒子フィルタなどの推定手法が適用可能となる.さらに,実際の適用例として,北海道南西沖地震津波の沿岸潮位計データと,津波シミュレーションモデルを同化した結果について与える.津波シミュレーションモデルにおいては,境界条件たる海底地形データセットに大きな不確実性が存在する.これを修正することにより,新たな海底地形についての知見を得ることが可能となる.
講演者: 吉田亮氏 (統計数理研究所)
演題: Beyesian data assimilation of in silico regulatory networks of biochemical molecules by using Hybrid Functional Petri Net
講演概要: Molecular regulatory networks of a living cell are comprised of a series of several biochemical reactions, e.g. phosphorylation and binding of protein molecules, gene regulations by transcription factors, G-protein coupling signaling, ubiquitin-proteasome system. In silico modeling of the biological networks, based on biochemical rate equations, provides a rigorous tool for unraveling the complex machinery of molecular regulations. Currently, we are developing the statistical technologies of data-driven construction of in silico network models. The method involves the following process: (1) Model building with Hybrid Functional Petri Net (HFPN) based on a consensus knowledge of biological system (2) Estimation of model parameters (biochemical rate constant) with Bayesian regularizer (3) Model evaluation and selection (4) Remodeling where needed. We address these tasks based on the generalized state space models. Main task of network profiling is to estimate the effective values of biochemical rate constant that are difficult to measure directly in vivo. To this end, we exploit time course measurements of gene expressions. In silico network models usually describe regulatory mechanisms of protein-level activities that are unobserved from gene expression measurements directly, thereby, yielding ill-posedness in the system identification. To avoid such an ill-posed problem, we develop the Bayesian regularizer which incorporates the external biological knowledge into the parameter estimation algorithm. Another important issue that we consider is the statistical evaluation and creation of hypothetical in silico models. We present a new Bayesian information theoretic-based measure to evaluate the predictability and biological robustness of the constructed model. This results in finding of the inconsistencies between the constructed model and experiments indicating aspects of the mechanism that require model revision.
講演者: 金森敬文氏 (名古屋大学)
演題: ブースティングのロバスト化と正則化
講演概要: 機械学習の分野で提案された判別分析の方法であるブースティングについて,主に統計的な側面を解説する.とくにロバスト化と正則化について述べる.ブースティングはサポートベクターマシンと並んで実データに広く応用されている.ブースティングでは判別境界の推定だけでなく,確率関数も推定することができる.これはサポートベクターマシンにはない特徴である.ブースティングでは,あまり性能が良くない弱判別機を多数組み合わせて判別精度の高い判別機を構成することができる.このような学習法は損失関数の座標降下法による逐次最適化として導出することができる.代表的な学習アルゴリズムであるアダブーストは,学習データがあまりノイズを含まなければ高い判別精度を達成できることが知られている.しかし学習データが外れ値のようなノイズを含む場合には,その影響で判別境界や確率関数の推定は不安定になる.本発表ではブースティングにおける損失関数と統計モデルとの関係について解説し,ロバスト統計の手法を用いてノイズの影響を受けにくいブースティング法を提案する.次に正則化について説明する.まず損失関数を適切に変形することで,確率分布の縮小推定量が得られることを示す.これは損失関数に正則化項を加えることに対応する.損失関数の変形をロバスト化したブースティングに組込むことで,分布関数の推定精度を向上させ,外れ値に対して頑健なブースティング法が得られると考えられる.正則化については,今後の課題として簡単に紹介するに留める.
講演者: 高井啓二氏 (大阪大学)
演題: 等式制約のあるEMアルゴリズム
講演概要: EMアルゴリズムは、一般に単純さと安定性を兼ね備えている。この単純さや安定性は、パラメタに等式制約がある場合に失われてしまう。従来は、ラグランジュ乗数法によりパラメタの制約を反映させてきた。しかし、この方法には、計算が複雑になってしまうという欠点があった。この欠点を、EM- stepの後に新たにP-stepを加えることにより、克服できることを示す。この方法の利点は、従来のEMアルゴリズムに対する拡張(ECMアルゴリズムなど)も利用できることである。P-stepを利用したいくつかの例を与える。ラグランジュ乗数法による収束までのステップ数よりも、このP-stepを用いたときの方が収束までのステップ数が少なくなる例も示す。
講演者: 山口和範氏 (立教大学)
演題: EMアルゴリズムとFinite Mixture Models
講演概要: 潜在クラスモデルをはじめとする混合モデルは古くからある統計モデルであるが、近年データマイニングで扱うような大規模データでのモデル化において注目されている。母集団を異質な集団の集まりとしてのモデル化がおこなわれたり、また、同質性の定義として統計モデルが利用されている。混合モデルにおける推定では、多くの場合、EMアルゴリズムが活用される。本報告では、EMアルゴリズムの基本的考え方と混合モデルでの活用法を紹介し、さらに、モデルの同定可能性の問題とEMアルゴリズムの関係を論じる。
講演者: Stefano M. Iacus氏(U. of Milan, Dep. of Economics, Business and Statistics)
演題: On Random Recursive Partitioning: an invariant and metric free matching method and its applications.
講演概要: In non randomized observational studies, matching of different samples (treated vs control units) is a prerequisite in order to estimate an average treatment effect. Motivated by this matching problem but not limited to it, a new algorithm to construct a proximity measure between observations has been developed. This proximity measure is invariant under monotonic transformation of the data and it is also free from any notion of distance or model. The method, called Random Recursive Partitiong (RRP) is a Monte Carlo method on the space of all possible non-empty and recursive partitions of the space generated by the observations. A 0-1 measure between observations is defined on each partition and the final proximity is obtained by averaging these measures over all the random partitions. RRP works also in the presence of missing values. Not much formal properties of the method are known yet, therefore Monte Carlo experiments are provided in order to show the performance of the method. Applications to average treatment effect estimation, classification and missing data imputation are also presented. A companion software is available in the form of a package for the R statistical environment.
講演者: 西山陽一氏(統計数理研究所)
演題: Donskerの不変原理と確率過程のノンパラメトリック推測
講演概要: Donskerの不変原理とは、経験過程が汎関数の意味で Brownian bridgeに弱収束することを・wす。これを、集合や関数の族によって添字づけられた確率場に対する理論にまで一般化する研究が Dudley や Pollardをはじめとする人々によってなされてきた。(学習理論を研究されている方は VC 次元との関連で周知のことであろう。)1996 年に出版されたvan der Vaart and Wellner の本は、この理論の i.i.d.の枠組みにおける諸結果のわかりやすい解説と、その統計的応用を与えるものであった。報告者の研究目標は、この理論をマルチンゲールの枠組みまで一般化し、確率過程の統計的推測へのさまざまな応用を産み出すことである。もちろん、このプロジェクトは発展途上である。本報告の前半部分では、i.i.d.の場合の解説からはじめて、マルチンゲールに一般化するための鍵となるアイデアの説明まで行う。(時間の関係で、最新理論の詳細な叙述はしない。)本報告の後半部分では、その理論のレヴィ過程のノンパラメトリック推測への応用を述べる。具体的には2つの結果を報告する。1つ目は、Nelson-Aalenタイプの推定量の無限次元空間における漸近正規性および漸近有効性である。2つ目は、レヴィ測度が観測時間区間のある一点において変化したかどうかを検定する問題(いわゆる変化点問題)である。
講演者: 庄野 宏氏(遠洋水産研究所)
演題: 統計モデルとデータマイニング手法の水産資源解析への応用
講演概要: 本発表では、水産資源解析学における様々な問題、特に魚の資源密度に対応し、相対的な資源量を表すCPUE(catch per unit effort: 単位努力当たり漁獲量)の解析に関する様々な問題について、遠洋域に生息するまぐろ類・関連種の漁業データや計算機によるシミュレーション実験を利用し、統計モデル及びデータマイニング的なアプローチにより問題解決するための手法を提案する。主に、季節・海区・漁具など様々な時空間的な要因や環境要因などを含んでいるCPUEデータから資源密度以外の影響を取り除いて資源の年変動に対応する部分を抽出する“CPUE標準化”に焦点を合わせて、以下の3つの問題について検討する。 1)CPUE・W準化を想定した一般化線形モデル(共分散分析モデル)における、様々な情報量規準やstepwise検定による要因効果の取捨選択、及びモデルの性能評価 2)ニューラルネットワークによるミナミマグロの操業がない時空間のCPUE予測、及び簡便な要因分析法の提案 3)ゼロキャッチ・データを多く含む場合におけるTweedieモデルの性能評価、及び従来の手法(adhocな共分散分析モデル・Catch型モデル)との比較
講演者: 荘島宏二郎氏 (独立行政法人 大学入試センター)
演題: 項目反応理論のいま,そしてこれから
講演概要: IRTモデルは,現象を記述する上では,非常に貧弱なモデル(模型)である.多値モデル,多次元モデルなどのIRTモデルの展開は,上記のような貧困さを克服するために進化して言ったといえる.本発表でも,そのような展開を踏まえて,遺伝的アルゴリズムを用いたIRTモデリング,ガンベルモデル,非補償モデル,ルーブリックIRTモデリングなどを紹介していく.さらに,それらを踏まえたうえで,今後のIRTの課題について論じる.
講演者: 下平英寿氏(東京工業大学)
演題: マルチスケール・ブートストラップ法による近似的な不偏検定
講演概要: 高度なデータ解析手法がブラックボックス化されている現状を考慮し,例えば階層的クラスタリングにおいてデータがクラスタを支持したか否か,またはグラフィカルモデルで枝があるか無いか,といった二値情報とリサンプリングだけを用いてp値を計算したい.ブートストラップ確率(支持頻度)がしばしば用いられるが,漸近バイアスが1次の精度しかなく,これを改良する試みがなされてきた.従来の漸近理論では仮説境界が滑らかな曲面であると仮定したテーラー展開によってバイアス補正項を導出していた.しかし多重比較などの応用では仮説の形状は錐であり,頂点付近で理論が破綻する.そこでテーラー展開のかわりにフーリエ変換にもとづいた漸近理論を導出した.驚くべきことに,ブートストラップ確率でサンプルサイズn’=−n(オリジナルデータのサイズにマイナス1をかけたもの)と形式的におくことによって不偏なp値が表現できることが分かった.実際にはいくつかのn’>0におけるブートストラップ確率を計算し,それにある変換を施したものをn’=−nへ外挿することによりp値を計算する.
講演者: 市川雅教氏(東京外国語大学)
演題: 共分散行列の関数に対する2次の精度を持つ信頼区間について
講演概要: 因子分析や構造方程式モデリングにおける母数は共分散行列の関数である. これらに対する信頼区間の構成について概観する.
通常は, 推定値とその標準誤差を用いた正規近似にもとづく方法が使われる. しかし, 観測変数の数に比べて標本の大きさが十分でない場合など, その精度が不十分であると感じられることが少なくない. より精度の高い信頼区間を得るための方法は2つに大別される. ひとつは解析的方法で, 推定量の分布の漸近展開を導出してその結果を利用するのはその例である. もうひとつは, 複雑な解析的導出をコンピュータによる大量の反復計算で置き換える数値的な方法, すなわちブートストラップ法である.
ここでは, コーニッシュ・フィッシャー展開に基づく方法, ブートストラップ-t 法, BCa 法, ABC 法の4種類の方法を取り上げる. 因子分析モデルの共通性 (標準化したものとしないもの) について, 正規近似による方法とこれら4種類の方法を数値例ならびに数値実験により比較する.
講演者: 福水健次氏(統計数理研究所)
演題: 正定値カーネルを用いたデータ解析
講演概要: 正定値カーネルとそれに付随して定まる再生核ヒルベルト空間を用いたデータ解析の方法論、いわゆるカーネル法に関する入門的な解説と、その方法論にもとづいて講演者らが研究している、回帰問題における次元削減の新しい方法に関して述べる。 カーネル法は、サポートベクターマシンの成功以来、急速に発展してきた・法論であるが、それは、関数の値がヒルベルト空間の内積として与えられるという「再生性」にもとづいた、データの非線形変換ないしはベクトル化の方法論であり、その方法論によって、さまざまな古典的線形手法がカーネル化できることを解説する。 次にその方法論を用いて、確率変数の独立性や条件付独立性が、再生核ヒルベルト空間によって特徴づけられることを説明する。 さらに、条件付独立性の特徴づけを用いると、回帰問題における説明変数の次元削減の方法「カーネル次元削減法」が導出できることを説明する。この方法は、既存の次元削減法と比べて、周辺分布や条件付確率に関する制約がほとんどいらない、きわめて広い問題に適用可能な方法である。講演ではその応用例に関しても述べる。
講演者: John Copas 氏 (U. of Warwick, Dept of Statistics)
演題: Selection bias and sensitivity analysis
講演概要: Selection bias is one of the most difficult problems in statistics, particularly in observational data analysis. Examples include missing data, hidden confounding, non-compliance, informative censoring, and publication bias. Unless we make very strong assumptions, such as 'missing at random', there is no complete solution. However, a sensitivity analysis can sometimes be useful. I will discuss some possible approaches to sensitivity analysis, with recent examples in medical research.
講演者: 江口真透氏(統計数理研究所)
演題: U-entropy, U-estimation and U-model
講演概要: A convex function U associates with U-entropy, U-divergence, which leads to U-estimation under a statistical model setting. Thus a class of convex functions presents that of statistical methods including the maximum likelihood. A simple condition of U gurantees robsutness of the U-estimator, which can be extended to integrating local learning beyond outlying robustness. A model of maximum U-entropy distributions, called U-model, is shown to attain a minimax solution in a game between Nature and decision maker. In the application to pattern recognition U-boost leaning algorithm is proposed by combing U-model and U-estimation in a sequential manner.
講演者: 高田佳和氏(熊本大学・工学部・教授)
演題: 二段階推測法のすすめ
講演概要: 統計的推測方法を実際に適用するとき(既にある標本ではなく、これから標本を抽出し、それにもとづいて推測を行う)に問題になるのが標本数の決定である。例えば、正規母集団の母平均の推測を考えよう。ただし、母標準偏差は未知とする。母平均の推定(点推定、区間推定)を標本平均で行うとき標本数をいくらにすればよいのか。標本数を決める一つの方法として、推定精度(点推定の場合は標準誤差、区間推定の場合は信頼区間の長さ)を指定することが考えられる。その場合標本数を決めるにはどうすればよいか。また、仮説検定ではt検定が用いられる。その標本数を決めるには、対立仮説と帰無仮説の母平均の差ではなく、その差を母標準偏差で割った値を指定しなければならない。しかし、母平均の差を指定する方が実際的な意味づけができる場合もある。その場合どうすればよいのか。残念ながら、事前に標本数を決めると、これらの推測問題を解くことができない。これらの推測問題を解くために考案された手法がスタインの二段階推測法である。その手法を適用すると、これらの推測問題がどのように解決されるのか、更に、最良母集団の選択問題への応用について概説する。
講演者: 藤澤洋徳氏(統計数理研究所・数理推論研究系・助教授)
演題: 外れ値の割合が多い場合にもバイアスが小さいロバスト推定
講演概要: In the conventional approach to robust parameter estimation, the influence function and breakdown point are often used as indexes of robustness in parameter estimation. However, they never guarantee that the bias caused by outliers is small in the case where the rate of outliers is not small, in other words, in the case of heavy contamination. This paper focuses on a certain cross entropy and divergence, which enable us to reasonably deal with the case of heavy contamination. We see that the bias caused by outliers can become sufficiently small even in the case of heavy contamination. The proposed method can be shown to be a kind of projection from the viewpoint of a Pythagorean relation, which is why it works well. In addition, it is proved that the method of parameter estimation with a sufficiently small bias even in the case of heavy contamination is essentially unique under some conditions.
演題: 臨床研究とAcademic Research Organization
講演概要: 新しい治療薬や治療法の開発のために、また医療における未解決の問題を・セするために、多くの臨床研究が実施されている。臨床研究は、適切に計画され、実施され、結果をエビデンスとして広く発信していく必要がある。その各段階における統計的な検討、すなわち1)計画時の研究デザイン、対象集団、評価項目、解析方法、サンプルサイズ、割付方法の設定、2)実施中の進捗把握、中間解析、および3)解析の実施と報告等は重要であり、生物統計家を含めた医師、臨床薬理や倫理の専門家、データマネジャー、リサーチナースなどのチームで研究を進める必要がある。さらに、幅広い疾患領域にわたる様々なデザインの臨床研究を多数実施するには、研究を支援する各機能が、有機的かつ効率的に働く組織が求められる。米国におけるAcademic ResearchOrganization(ARO)の現状を紹介しながら、今後より効率的に臨床研究を進めるために必要なAROの機能、役割、重要性について述べる。また、実際に医療機関において生物統計家として数多くの臨床研究を推進している中で遭遇する統計的問題についての事例紹介も行う予定である。
講演者: 前田新一氏(奈良先端科学技術大学院大学・論理生命学分野・助手)
演題: 非線形ノイズつき独立成分分析による音高知覚モデル
講演概要: 本発表では、非線形ノイズつき独立成分分析(nonlinear noisy ICA)の提案とそれを利用した音高知覚メカニズムを説明するモデルについて述べる。
独立成分分析ではBlind Source Separation問題を扱う。Blind SourceSeparation問題では、互いに独立であるという情報以外は未知である信号の存在を仮定し、観測信号としてそれら独立な信号の線形混合が得られることを仮定する。これら観測信号のみから線形変換によって、もとの独立成分を順序とスケールを除いて復元する手法を独立成分分析と呼んでいる。
独立成分分析の一般化として、これまでに線形混合を非線形混合に一般化した非線形ノイズなし独立成分分析と線形混合後にガウスノイズが加わるとした線形ノイズつき独立成分分析が知られている。ここでは、非線形混合後にガウス・mイズが加わると仮定したより一般的な状況を考え、最尤推定によってもとの独立信号を推定する学習則を導出した。これによって、これまでの最尤推定やエントロピー最大化基準に基づく線形ノイズ付き独立成分分析や非線形ノイズ付き独立成分分析との関係を明らかにし、これまでの線形ノイズ付き独立成分分析で存在した問題点を克服することができた。
最後に、非線形ノイズつき独立成分分析を考える動機となった音高知覚モデルへの適用について述べる。
講演者: 濱崎俊光氏(大学院医学系研究科・医学統計学・助教授)
演題: 臨床評価における統計的方法
講演概要: 最近,科学的根拠に基づく医療(Evidence Based Medicine: EBM, Sackett et al., 1997)の重要性が喚起されるに伴い,医療・医薬品の臨床研究では,(確率化)臨床試験が,治療効果を比較するための科学的で最も説得力のある手段とし て位置づけられている.そして,多種の疾患に対して,数多くの治療法が次々に評価の俎上にあがり,多様なデザインの臨床試験が並行して計画・遂行されてい る.臨床試験は,「ヒト」を対象として実施される,医薬品や医療技術といった治療の有効性と安全性を検討するための実験研究である.「科学的に」処するこ とは,いいかえれば,「事実を反映した(正しい)」データに基づいて判断をくだすことであり,このような場面では否応なく統計的方法論に立脚せねばならな い素地が拡大してくる.しかも,臨床試験の倫理性,および有効性の高い治療の開発とその効率化に注意を喚起することは必然的に,臨床試験の実験研究として の計画面と戦略面に重点をおくことを強いることになる.とくに,実験研究でのデータは実地の智慧を活かした相当に巧妙な設計(デザイン)のもとに蒐集され ないと,仮説の検証・探索で効用を発揮しない.本講演では,臨床試験の計画・実施で必須となる統計的考え方を網羅的に論じる.また,二三の統計的問題につ いても簡単に触れる.
Sackett, D.L., Richardson, W.S., Rosenberg, W. & Haynes, R.B. (1997). Evidence-Based Medicine: How to Practice and Teach EBM. London: Churchill- Living-stone
{kind=link}
{kind=link}